
Seien Sie am 30. April dabei: Vorstellung von Parasoft C/C++test CT für kontinuierliche Tests und Compliance-Exzellenz | Registrierung
Zum Abschnitt springen
So verhindern Sie Pufferüberlauf und andere Fehler bei der Speicherverwaltung

28. November 2023
10 min lesen
Wenn die Datenmenge die Speicherkapazität des Speicherpuffers überschreitet, kommt es zu einem Pufferüberlauf. Sehen Sie sich an, wie die Static Analysis Checker-Funktion in der Parasoft C/C++-Lösung Ihnen helfen kann, Fehler aufgrund von Pufferüberläufen zu verwalten.
Zum Abschnitt springen
Zum Abschnitt springen
Die Speicherverwaltung birgt Gefahren, insbesondere in C und C++. Tatsächlich machen Fehler im Zusammenhang mit Speicherverwaltungsschwächen einen beträchtlichen Teil der CWE Top 25 aus. Acht der Top 25 stehen in direktem Zusammenhang damit Puffer läuft über, schlechte Zeiger und Speicherverwaltung.
Die mit Abstand größte Softwareschwäche ist CWE-119, „Unsachgemäße Beschränkung von Operationen innerhalb der Grenzen eines Speicherpuffers“. Diese Arten von Fehlern spielen eine herausragende Rolle bei Sicherheitsproblemen in allen Arten von Software, einschließlich sicherheitskritischer Anwendungen in Automobilen, medizinischen Geräten und Avionik.
Hier sind die Speicherfehler im Zusammenhang mit allgemeinen Schwachstellenaufzählungen aus den CWE Top 25:
| Rang | ID | Name und Vorname |
|---|---|---|
| [1] | CWE-787 | Außerhalb der Grenzen schreiben |
| [4] | CWE-416 | Verwenden Sie nach Frei |
| [7] | CWE-125 | Außerhalb der Grenzen lesen |
| [12] | CWE-476 | NULL-Zeiger-Dereferenzierung |
| [14] | CWE-190 | Integer Overflow oder Wraparound |
| [17] | CWE-119 | Unsachgemäße Einschränkung von Operationen innerhalb der Grenzen eines Speicherpuffers |
Obwohl diese Fehler C, C ++ und andere Sprachen seit Jahrzehnten plagen, treten sie heute immer häufiger auf. Sie sind gefährliche Fehler in Bezug auf Konsequenzen für Qualität, Sicherheit und Zuverlässigkeit, und ihre Anwesenheit ist eine der Hauptursachen für Sicherheitslücken.
Was sind Pufferüberläufe?
Ein Pufferüberlauf tritt auf, wenn mehr Daten in einen Speicherabschnitt oder Puffer geschrieben werden, als dieser aufnehmen kann, beispielsweise wenn Sie versuchen, 12 Buchstaben in ein Feld einzufügen, das nur 10 Buchstaben enthält. Dies kann zum Überschreiben des angrenzenden Speichers führen Leerzeichen, was zu unvorhersehbarem Verhalten in einem Programm führt.
Pufferüberlauffehler können die Qualität, Sicherheit und Zuverlässigkeit von Software erheblich beeinträchtigen. Aus Sicherheitsgründen können böswillige Akteure Pufferüberlauffehler ausnutzen, um beliebigen Code auszuführen oder den Betrieb eines Systems zu stören. Dies liegt daran, dass ein Angreifer bei einem Pufferüberlauf möglicherweise steuern kann, welche Daten über den Puffer hinaus geschrieben werden, und so möglicherweise den Ausführungsfluss des Programms ändern kann.
Daher ist es für Entwickler von entscheidender Bedeutung, eine robuste Datenverarbeitung zu implementieren und ihre Software ordnungsgemäß zu testen, um dies zu verhindern Pufferüberlauf Fehler vermeiden und die Integrität und Sicherheit ihrer Software wahren.
Hauptursache für Sicherheitslücken
Microsoft entdeckt dass in den letzten 12 Jahren über 70 % der Sicherheitslücken in ihren Produkten darauf zurückzuführen waren Probleme mit der Speichersicherheit. Diese Art von Fehlern stellt die größte Angriffsfläche für ihre Anwendung dar und wird von Hackern genutzt. Ihren Untersuchungen zufolge waren Heap-Out-of-bounds, Use-after-free und nicht initialisierte Nutzung die Hauptursachen für Sicherheitsangriffe. Sie weisen darauf hin, dass die Schwachstellenklassen schon seit 20 Jahren oder länger existieren und auch heute noch weit verbreitet sind.
In ähnlicher Weise hat Google herausgefunden, dass 70 % der Sicherheitslücken im Chromium-Projekt, der Open-Source-Basis für den Chrome-Browser, auf dieselben Speicherverwaltungsprobleme zurückzuführen sind. Ihre Hauptursache war ebenfalls „Use-after-free“, gefolgt von anderer unsicherer Speicherverwaltung.
Angesichts dieser Beispiele realer Erkenntnisse ist es wichtig, dass Softwareteams diese Art von Fehlern ernst nehmen. Glücklicherweise gibt es Möglichkeiten, diese Art von Problemen mit einer effektiven und effizienten statischen Analyse zu verhindern und zu erkennen.
Wie Speicherverwaltungsfehler zu Sicherheitslücken führen
In den meisten Fällen sind Speicherverwaltungsfehler das Ergebnis schlechter Programmierpraktiken bei Verwendung von Zeigern in C / C ++ und direktem Zugriff auf den Speicher. In anderen Fällen hängt es damit zusammen, dass schlechte Annahmen über die Länge und den Inhalt von Daten getroffen werden.
Diese Software-Schwachstellen werden am häufigsten mit fehlerhaften Daten ausgenutzt, Daten von außerhalb der Anwendung, die nicht auf Länge oder Format überprüft wurden. Das berüchtigte Heartbleed Bei einer Sicherheitsanfälligkeit wird ein Pufferüberlauf ausgenutzt. Technisch gesehen ist es ein Puffer überlesen. Wie wir in unserem vorherigen Blog besprochen haben SQL-InjektionenDie Verwendung von Eingaben, die nicht überprüft und nicht eingeschränkt sind, ist ein Sicherheitsrisiko.
Betrachten wir einige der Hauptkategorien von Schwachstellen in der Speicherverwaltungssoftware. Das übergeordnete ist CWE-119: Unsachgemäße Einschränkung von Operationen innerhalb der Grenzen eines Speicherpuffers.
Pufferüberlauf
Programmiersprachen, am häufigsten C und C++, die einen direkten Zugriff auf den Speicher ermöglichen und nicht automatisch überprüfen, ob die Speicherorte gültig und anfällig für Zugriffe sind Speicherbeschädigungsfehler. Diese Beschädigung kann in Daten- und Codebereichen des Speichers auftreten, wodurch vertrauliche Informationen offengelegt werden, zu einer unbeabsichtigten Codeausführung führen oder zum Absturz einer Anwendung führen kann.
Das folgende Beispiel zeigt einen klassischen Fall eines Pufferüberlaufs von CWE-120:
char last_name[20];
printf ("Enter your last name: ");
scanf ("%s", last_name);In diesem Fall gibt es keine Einschränkung für die Benutzereingabe von scanf () noch die Grenze für die Länge von Familienname, Nachname ist 20 Zeichen. Wenn Sie einen Nachnamen mit mehr als 20 Zeichen eingeben, wird die Benutzereingabe über die Grenzen des Puffers hinaus in den Speicher kopiert Familienname, Nachname. Hier ist ein subtileres Beispiel aus CWE-119:
void host_lookup(char *user_supplied_addr){
struct hostent *hp;
in_addr_t *addr;
char hostname[64];
in_addr_t inet_addr(const char *cp);
/*routine that ensures user_supplied_addr is in the right format for conversion */
validate_addr_form(user_supplied_addr);
addr = inet_addr(user_supplied_addr);
hp = gethostbyaddr( addr, sizeof(struct in_addr), AF_INET);
strcpy(hostname, hp->h_name);
}Diese Funktion verwendet eine vom Benutzer bereitgestellte Zeichenfolge, die eine IP-Adresse enthält, beispielsweise 127.0.0.1, und ruft den Hostnamen dafür ab.
Die Funktion validiert die Benutzereingabe (gut!), Überprüft jedoch nicht die Ausgabe von gethostbyaddr () (schlecht!) In diesem Fall reicht ein langer Hostname aus, um den Hostnamenpuffer zum Überlaufen zu bringen, der derzeit auf 64 Zeichen begrenzt ist. Beachten Sie, dass wenn gethostaddr () Gibt eine Null zurück, wenn ein Hostname nicht gefunden werden kann. Es gibt auch einen Nullzeiger-Dereferenzierungsfehler!
Use-After-Free-Fehler
Interessanterweise stellte Microsoft in seiner Studie fest, dass Use-After-Free-Fehler die häufigsten Probleme bei der Speicherverwaltung waren. Wie der Name schon sagt, bezieht sich der Fehler auf die Verwendung von Zeigern im Fall von C/C++, die auf zuvor freigegebenen Speicher zugreifen. C und C++ verlassen sich normalerweise darauf, dass der Entwickler die Speicherzuweisung verwaltet, was oft schwierig zu erledigen ist. Wie das folgende Beispiel aus CWE-416 zeigt, kann man oft leicht davon ausgehen, dass ein Zeiger noch gültig ist:
char* ptr = (char*)malloc (SIZE);
if (err) {
abrt = 1;
free(ptr);
}
...
if (abrt) {
logError("operation aborted before commit", ptr);
}Im obigen Beispiel der Zeiger ptr ist frei, wenn ein Fehler wahr ist, wird aber später nach der Freigabe dereferenziert, wenn abr ist wahr, was auf wahr gesetzt wird, wenn sich irren ist wahr. Das mag gekünstelt erscheinen, aber wenn sich zwischen diesen beiden Codeschnipseln viel Code befindet, kann man das leicht übersehen. Darüber hinaus kann dies nur bei einer Fehlerbedingung auftreten, die nicht ordnungsgemäß getestet wird.
NULL-Zeiger-Dereferenzierung
Eine weitere häufige Softwareschwäche ist die Verwendung von Zeigern oder Objekten in C++ und Java, von denen erwartet wird, dass sie gültig sind, die aber NULL sind. Obwohl diese Dereferenzierungen in Sprachen wie Java als Ausnahmen abgefangen werden, können sie dazu führen, dass eine Anwendung angehalten, beendet oder abstürzt. Nehmen Sie das folgende Beispiel in Java aus CWE-476:
String cmd = System.getProperty("cmd");
cmd = cmd.trim();Dies sieht harmlos aus, da der Entwickler annehmen könnte, dass die getProperty () Methode gibt immer etwas zurück. In der Tat, wenn die Eigenschaft "Cmd" existiert nicht, wird ein NULL zurückgegeben, was bei Verwendung eine NULL-Dereferenzierungsausnahme verursacht. Obwohl dies gutartig klingt, kann es dazu führen katastrophale Folgen.
In seltenen Fällen ist das Schreiben oder Lesen von Speicher möglich, wenn NULL der 0x0-Speicheradresse entspricht und privilegierter Code darauf zugreifen kann, was zur Codeausführung führen kann.
Effektive Minderungsstrategien
Es gibt verschiedene Abhilfemaßnahmen, die Entwickler implementieren sollten. In erster Linie müssen Entwickler sicherstellen, dass Zeiger für Sprachen wie C und C ++ gültig sind, und zwar mit verifizierter Logik und gründlicher Überprüfung.
Für alle Sprachen ist es unbedingt erforderlich, dass Code oder Bibliotheken, die den Speicher manipulieren, Eingabeparameter validieren, um einen Zugriff außerhalb der Grenzen zu verhindern. Im Folgenden finden Sie einige verfügbare Optionen zur Schadensbegrenzung. Entwickler sollten sich jedoch nicht darauf verlassen, dass sie schlechte Programmierpraktiken ausgleichen.
Wahl der Programmiersprache
Einige Sprachen bieten integrierten Schutz vor Überläufen wie Ada und C #.
Verwendung sicherer Bibliotheken
Die Verwendung von Bibliotheken wie der Safe C-Zeichenfolgenbibliothek, die integrierte Überprüfungen zur Vermeidung von Speicherfehlern bieten, ist verfügbar. Es sind jedoch nicht alle Pufferüberläufe das Ergebnis einer Zeichenfolgenmanipulation. Ansonsten sollten Programmierer immer auf Funktionen zurückgreifen, die die Länge von Puffern als Argumente verwenden, z. strncpy () gegen strcpy ().
Kompilierung und Laufzeithärtung
Dieser Ansatz verwendet Kompilierungsoptionen, die der Anwendung Code hinzufügen, um die Verwendung von Zeigern zu überwachen. Dieser hinzugefügte Code kann verhindern, dass zur Laufzeit Überlauffehler auftreten.
Härten der Ausführungsumgebung
Betriebssysteme verfügen über Optionen, um die Ausführung von Code in Datenbereichen einer Anwendung zu verhindern, z. B. einen Stapelüberlauf mit Code-Injection. Es gibt auch Optionen zum zufälligen Anordnen der Speicherzuordnung, um zu verhindern, dass Hacker vorhersagen, wo sich ausnutzbarer Code befinden könnte.
Trotz dieser Abschwächungen gibt es keinen Ersatz für geeignete Codierungspraktiken, um Pufferüberläufe überhaupt zu vermeiden. Daher sind Erkennung und Vorbeugung von entscheidender Bedeutung, um das Risiko dieser Softwareschwächen zu verringern.
Verschieben Sie die Erkennung und Beseitigung von Pufferüberläufen
Die Übernahme eines DevSecOps-Ansatzes für die Softwareentwicklung bedeutet die Integration von Sicherheit in alle Aspekte der DevOps-Pipeline. Genauso wie Qualitätsprozesse wie Codeanalyse und Unit-Tests werden so früh wie möglich vorangetrieben bei SDLC gilt dasselbe für die Sicherheit.
Pufferüberläufe und andere Speicherverwaltungsfehler könnten der Vergangenheit angehören, wenn die Entwicklungsteams einen solchen Ansatz allgemeiner anwenden würden. Wie Untersuchungen von Google und Microsoft zeigen, machen diese Fehler immer noch 70% ihrer Sicherheitslücken aus. Lassen Sie uns unabhängig davon einen Ansatz skizzieren, der sie so früh wie möglich verhindert.
Das Auffinden und Beheben von Speicherverwaltungsfehlern zahlt sich im Vergleich zum Patchen einer freigegebenen Anwendung aus. Der unten beschriebene Ansatz zum Erkennen und Verhindern basiert auf der Verlagerung der Minderung von Pufferüberläufen nach links in die frühesten Entwicklungsstadien. Und dies durch Erkennung durch statische Code-Analyse zu verstärken.
Entdeckung
Das Erkennen von Speicherverwaltungsfehlern beruht auf einer statischen Analyse, um diese Arten von Schwachstellen im Quellcode zu finden. Die Erkennung erfolgt auf dem Desktop des Entwicklers und im Build-System. Es kann vorhandenen Code, Legacy-Code und Code von Drittanbietern enthalten.
Durch die kontinuierliche Erkennung von Sicherheitsproblemen wird sichergestellt, dass alle Probleme gefunden werden, die:
- Entwickler in der IDE verpasst.
- Bestehen Sie in Code, der älter ist als Ihr neuer Ansatz zum Erkennen und Verhindern.
Der empfohlene Ansatz ist ein Trust-But-Verify-Modell. Die Sicherheitsanalyse wird auf IDE-Ebene durchgeführt, wobei Entwickler anhand der erhaltenen Berichte Entscheidungen in Echtzeit treffen. Überprüfen Sie als Nächstes auf Build-Ebene. Im Idealfall besteht das Ziel auf Build-Ebene nicht darin, Schwachstellen zu finden. Es soll überprüft werden, ob das System sauber ist.
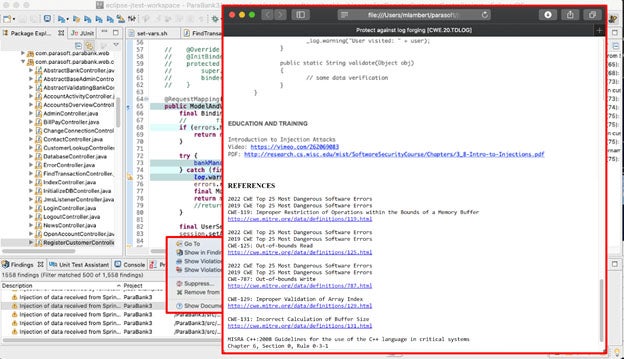
Parasoft C / C ++ test Dazu gehören statische Analyseprüfer für diese Arten von Speicherverwaltungsfehlern, einschließlich Pufferüberläufen. Betrachten Sie das folgende Beispiel aus dem C / C ++ - Test.
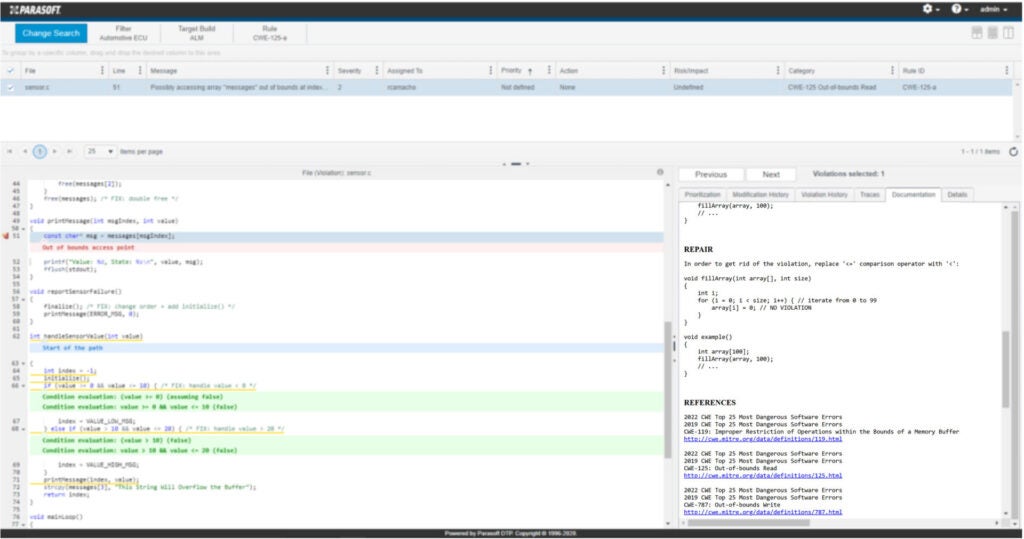
Vergrößern Sie die Details, die Funktion printMessage () Fehler erkennt den Fehler:
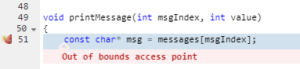
Der Parasoft C / C ++ - Test bietet auch Ablaufverfolgungsinformationen darüber, wie das Tool zu dieser Warnung gelangt ist:
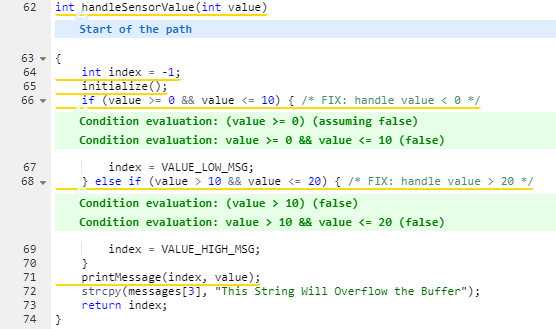
In der Seitenleiste werden Details zum Beheben dieser Sicherheitsanfälligkeit sowie entsprechende Verweise angezeigt:
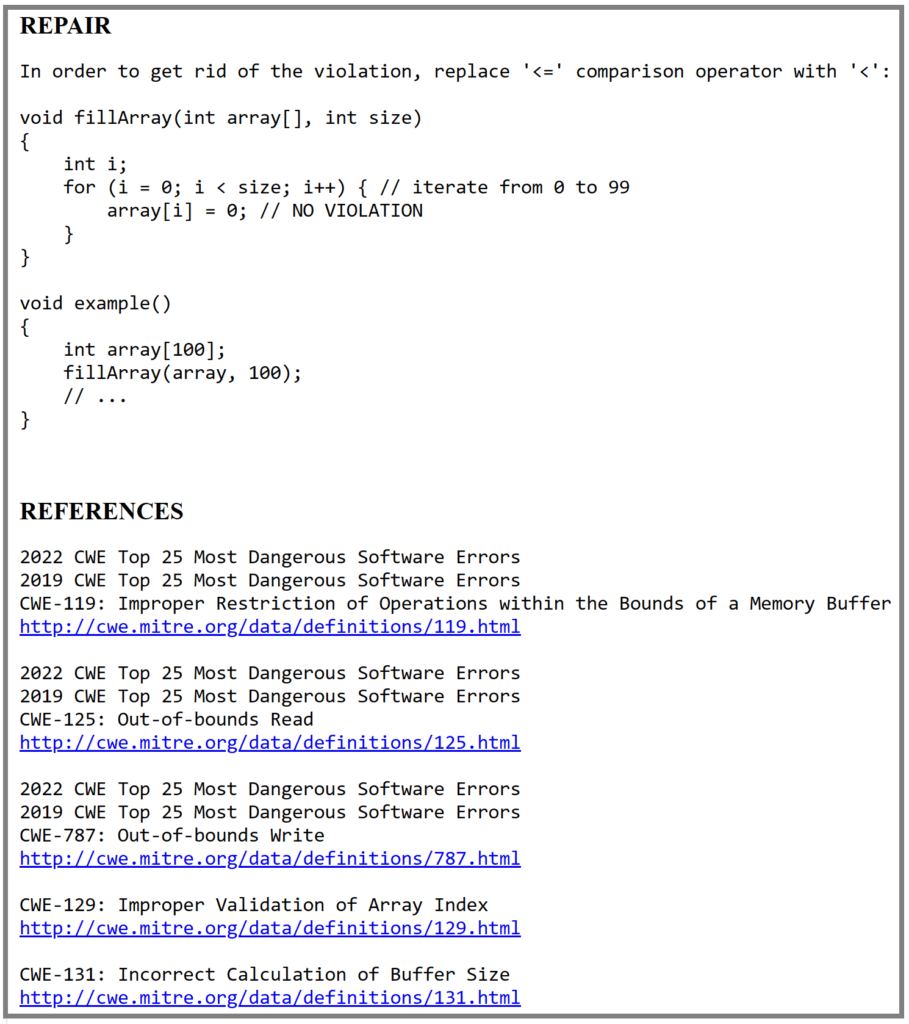
Eine genaue Erkennung sowie unterstützende Informationen und Korrekturempfehlungen sind entscheidend, damit statische Analysen und die frühzeitige Erkennung dieser Sicherheitsanfälligkeiten für Entwickler nützlich und sofort umsetzbar sind.
Verhindern von Pufferüberläufen und anderen Speicherverwaltungsfehlern
Die ideale Zeit und der ideale Ort, um Pufferüberläufe zu verhindern, ist, wenn Entwickler Code in ihre IDE schreiben. Teams, die sichere Codierungsstandards wie SEI CERT C für C und C ++ und OWASP Top 10 für Java und .NET oder CWE Top 25 anwenden, haben Richtlinien, die vor Speicherverwaltungsfehlern warnen.
CERT C enthält beispielsweise die folgenden Regeln für die Speicherverwaltung:

Zu diesen Regeln gehören präventive Codierungstechniken, die Speicherverwaltungsfehler von vornherein vermeiden. Jeder Regelsatz umfasst eine Risikobewertung zusammen mit den Abhilfekosten, sodass Softwareteams die Richtlinien wie folgt priorisieren können:
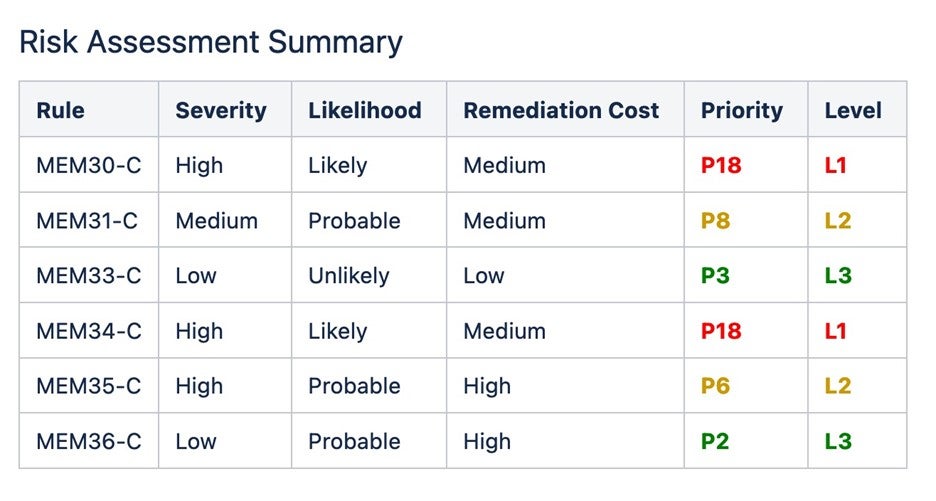
In der CERT C-Verwendung des Wortes „Regel“ führt ein Verstoß gegen eine Regel höchstwahrscheinlich zu einem Fehler, und die Einhaltung sollte automatisch oder manuell durch Überprüfung des Codes erfolgen. Regeln gelten als verbindlich. Ausnahmen bei Regelverstößen sind zu dokumentieren.
Andererseits bietet eine Empfehlung eine Anleitung, deren Befolgung die Sicherheit, Zuverlässigkeit und Sicherheit verbessern sollte. Ein Verstoß gegen eine Empfehlung bedeutet jedoch nicht zwangsläufig, dass ein Fehler im Code vorliegt. Empfehlungen sind nicht verpflichtend.
CERT C hat die folgenden Empfehlungen für die Speicherverwaltung:

Die zugehörige Risikobewertung für diese Empfehlungen lautet wie folgt:
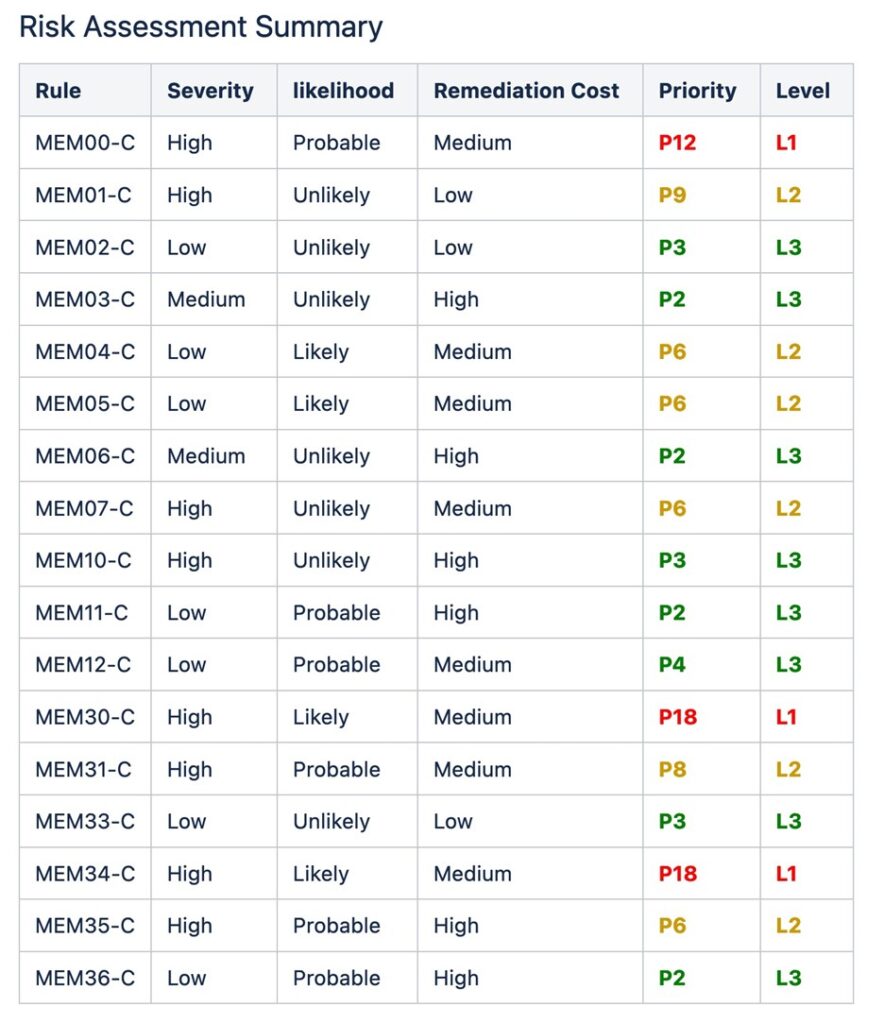
Eine wichtige Präventionsstrategie besteht darin, einen Codierungsstandard zu übernehmen, der an Branchenrichtlinien wie SEI CERT angepasst ist, und ihn bei der zukünftigen Codierung durchzusetzen. Die Vermeidung dieser Schwachstellen durch bessere Codierungspraktiken ist kostengünstiger, weniger riskant und bietet die höchste Kapitalrendite.
Das Ausführen einer statischen Analyse des neu erstellten Codes ist schnell und einfach. Es ist für Teams einfach, sich sowohl in die Desktop-IDE als auch in den CI / CD-Prozess zu integrieren. Um zu verhindern, dass dieser Code jemals in den Build aufgenommen wird, sollten Sie zu diesem Zeitpunkt alle Sicherheitswarnungen und unsicheren Codierungspraktiken untersuchen.
Ein ebenso wichtiger Aspekt bei der Erkennung schlechter Codierungspraktiken ist die Nützlichkeit der Berichte. Es ist wichtig, die Grundursache von Verstößen gegen die statische Analyse zu verstehen, um sie schnell und effizient zu beheben. Hier kommen kommerzielle Tools wie die von Parasoft zum Einsatz C / C ++ - Test, dotTEST und Test scheinen.
Die automatisierten Testtools von Parasoft bieten vollständige Spuren für Warnungen, veranschaulichen diese in der IDE und sammeln kontinuierlich Build- und andere Informationen. Diese gesammelten Daten bieten neben Testergebnissen und Metriken einen umfassenden Überblick über die Einhaltung des Codierungsstandards des Teams sowie über den allgemeinen Qualitäts- und Sicherheitsstatus.
Entwickler können Ergebnisse basierend auf anderen Kontextinformationen wie Metadaten zum Projekt, dem Alter des Codes und dem für den Code verantwortlichen Entwickler oder Team weiter filtern. Tools wie Parasoft mit künstlicher Intelligenz (KI) und maschinellem Lernen (ML) verwenden diese Informationen, um die kritischsten Probleme genauer zu bestimmen.
Die Dashboards und Berichte enthalten die Risikomodelle, die Teil der von OWASP, CERT und CWE bereitgestellten Informationen sind. Auf diese Weise verstehen Entwickler besser, welche Auswirkungen die vom Tool gemeldeten potenziellen Schwachstellen haben und welche dieser Schwachstellen priorisiert werden müssen. Alle auf IDE-Ebene generierten Daten korrelieren mit den oben beschriebenen nachgelagerten Aktivitäten.
Fazit: Schützen Sie Ihren Code vor Pufferüberläufen
Der Puffer läuft über und andere Speicherverwaltungsfehler plagen weiterhin Anwendungen. Sie bleiben eine der Hauptursachen für Sicherheitslücken. Trotz des Wissens darüber, wie es funktioniert und genutzt wird, bleibt es weit verbreitet. Siehe die IoT-Hall of Shame für aktuelle Beispiele.
Als Ergänzung zu aktiven Sicherheitstests schlagen wir einen Präventions- und Erkennungsansatz vor, der Pufferüberläufe so früh wie möglich im SDLC verhindert, bevor sie in den Code geschrieben werden. Das Verhindern solcher Speicherverwaltungsfehler in der IDE und deren Erkennung in der CI/CD-Pipeline ist der Schlüssel zum Entfernen dieser Fehler aus Ihrer Software.
Intelligente Softwareteams können Fehler bei der Speicherverwaltung minimieren. Mit den richtigen Prozessen, Tools und Automatisierung in ihren bestehenden Arbeitsabläufen können sie Einfluss auf Qualität und Sicherheit nehmen.



